Bittensor Partners with Harvard University: Chutes Optimizes AI Model
Key Takeaways
- A research team from Harvard University is using the Bittensor subnet Chutes for real-world tests to increase AI model efficiency.
- Through a new prefix caching algorithm, significant savings in computing power were achieved within the decentralized architecture.
- Users can provide data for research via an opt-in endpoint and receive significant discounts on their usage in return.
Introduction
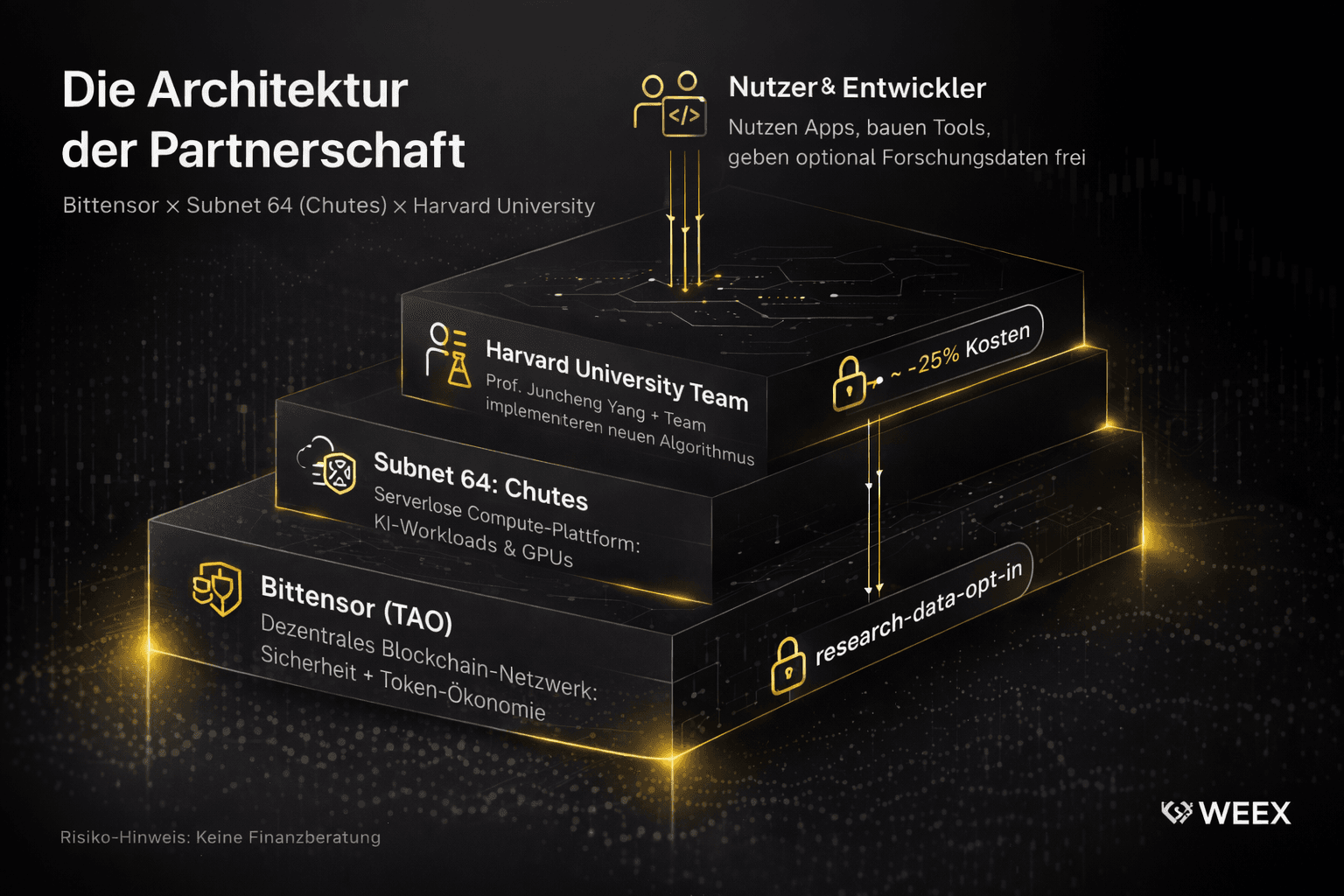
The news that the decentralized AI protocol Bittensor is partnering with Harvard University has caused quite a stir in the tech industry. Specifically, it is the serverless compute platform Chutes, which runs as subnet 64 on Bittensor, that is now collaborating with a research team from the renowned university. At the heart of this partnership is the optimization of LLM inference through advanced caching methods, which is increasingly making decentralized networks a serious competitor to established cloud providers.

Chutes Partners with Harvard: Details of the Collaboration
In March 2026, the development team behind the decentralized AI platform officially announced that Chutes is collaborating with a research team from Harvard University. Led by Prof. Juncheng Yang, an expert in efficient storage systems and machine learning at the Harvard School of Engineering and Applied Sciences, a new algorithm is being tested in real-world operations.
To provide this scientific work with sufficient production data, a special endpoint was established. Users of the platform can voluntarily opt into the program and receive a 25 percent price discount as an incentive for providing their inference data.
Technological Breakthrough via Prefix Caching
The technical core of this collaboration is so-called prefix caching. During text generation by large language models (LLMs), significant computational effort arises, particularly in the preparation phase. By storing and reusing already processed text segments, latency and hardware utilization can be drastically reduced, as confirmed by scientific publications on Learned Prefix Caching for LLM Inference.
In practice, the implementation of this concept leads to significant efficiency gains according to analysts from the SubnetEdge community. The required computing resources for inference on Chutes are said to have been reduced by up to 60 percent. This enormously strengthens the competitiveness of the decentralized infrastructure.
Significance for the Bittensor Ecosystem
The fact that Chutes is partnering with Harvard is not only a milestone for the specific subnet but a strong signal for the entire Bittensor network. Subnet 64 has established itself as a core infrastructure project for running AI models.
The validation of the technology by an elite academic institution like Harvard proves that decentralized networks are mature enough to process complex workloads in a resource-efficient manner. Since the endowment of Harvard University has previously shown openness to digital assets like Bitcoin, this cooperation fits seamlessly into the growing acceptance of Web3 technologies in the academic sector.
Conclusion
The direct partnership between Harvard University and the Bittensor subnet Chutes marks a massive strategic milestone for the entire project. The active research of an Ivy League institution lends enormous credibility to the decentralized sector. With this, the network impressively proves that blockchain-based infrastructures can now seriously compete with established cloud giants for dominance in the AI market.
FAQ - Frequently Asked Questions
What does the news that Bittensor is partnering with Harvard University mean?
The platform Chutes (subnet 64 on Bittensor) is working with a Harvard research team to increase the computational efficiency of large AI language models.
How do users benefit from Chutes partnering with Harvard?
Those who voluntarily share their data for research receive a 25% discount. In the long term, the optimization ensures a generally faster and cheaper AI infrastructure.
What exactly is prefix caching?
An optimization method that caches recurring AI inputs. Since these do not have to be recalculated every time, it saves an enormous amount of time and computing power.
WEEX | Rising Star of Crypto Exchanges in the DACH Region
WEEX combines security, innovation, and community with features for beginners and professionals:
Security & Protection
- 1,000 BTC Protection Fund: Self-funded reserve for rapid loss protection in exceptional cases
Trading & Earning
- Auto Earn: Daily automatic USDT earnings without effort
- Copy Trading: Follow elite traders automatically or apply as an elite trader for additional benefits
- WE-Launch: Early access to new projects – exclusive to WEEX users
Benefits & Rewards
- Promotions & Rewards: Trading competitions and special bonuses for active users
- Affiliate Program: Lifetime commissions from new users – details here
- VIP Benefits: Lowest fees, market insights, and personal support for high-volume traders
- WXT Token: Fee discounts, airdrops, and exclusive platform benefits
Discover current trends on WEEX Spot and start now: Register now
Disclaimer – Legal Notice from WEEX Exchange
WEEX and its affiliates offer services for the exchange of digital assets, including derivatives and margin trading, only where legal and to eligible users. All content is general information, not financial advice – seek independent advice before trading. Trading cryptocurrencies involves high risk and can lead to a total loss. By using WEEX services, you accept all associated risks and terms. Never invest more than you can afford to lose. Further information can be found in our Terms of Service and in the Risk Disclosure.
Follow WEEX on social media:
X: @WEEX_Official
Instagram: @WEEX Exchange
TikTok: @weex_global
YouTube: @WEEX_official
Discord: WEEX Community
Telegram: WeexGlobal Group
